Newsletter Subscribe
Enter your email address below and subscribe to our newsletter
Enter your email address below and subscribe to our newsletter

You know the routine. You’re standing in your kitchen, hands covered in flour, and you cheerfully shout, “Alexa, set a timer for twenty minutes.” You wait for that reassuring beep. Instead, the little cylinder on the counter lights up and confidently announces, “Okay, playing 1920s jazz hits on Spotify.”
Suddenly, your simple desire for perfectly baked cookies has turned into a speakeasy dance party.
It feels like our gadgets are either magical geniuses or stubborn teenagers who refuse to listen. We talk to cylinders, phones, and even thermostats as if they were people, expecting them to understand context, nuance, and our occasional mumbling. But have you ever stopped to wonder what is actually happening inside that plastic box?
How does a collection of microchips distinguish between “turn on the lights” and “turn on the news”? The answer is less like magic and more like a very fascinating, very fast game of telephone.
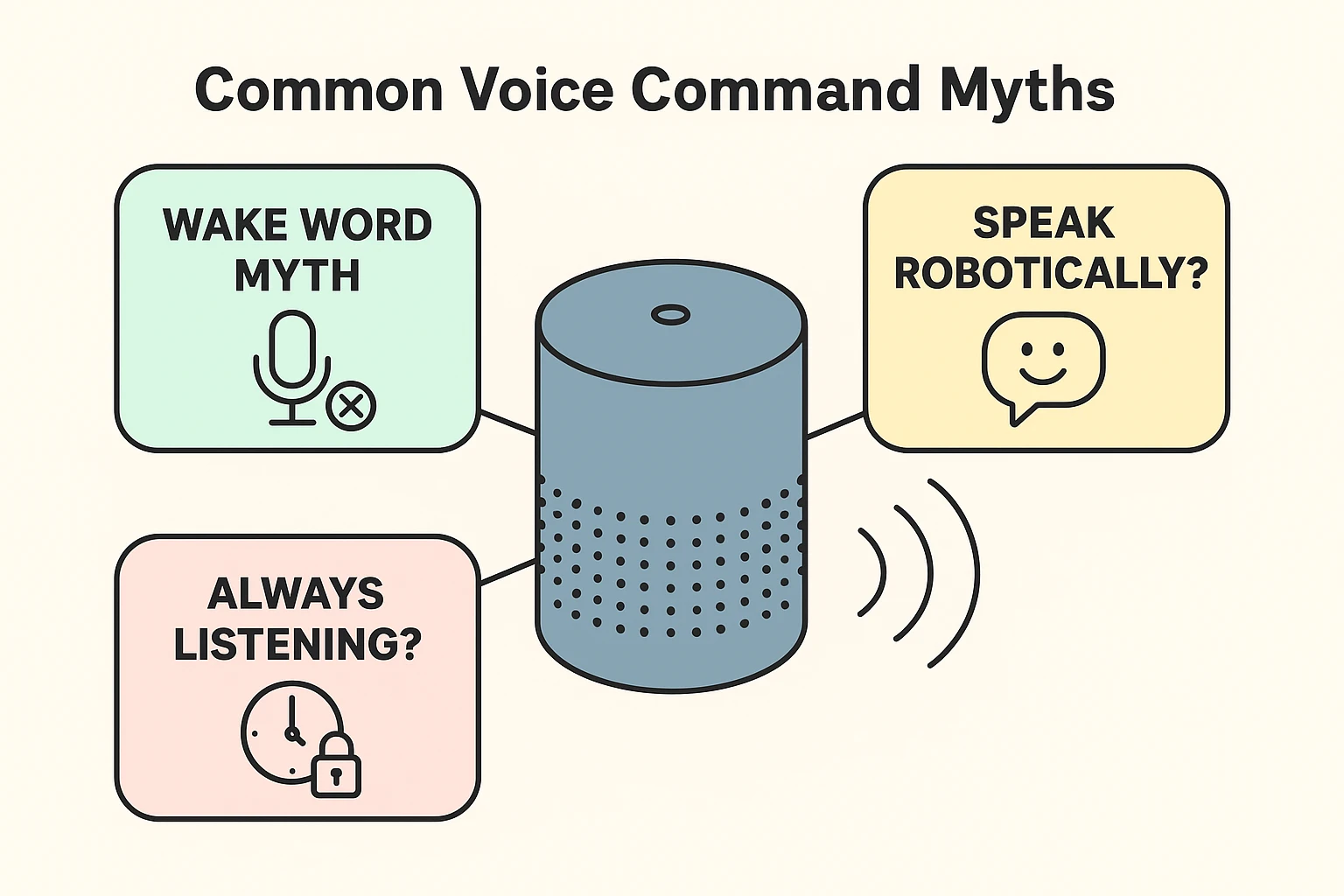
One of the biggest worries folks have—and rightfully so—is the idea that these devices are the digital equivalent of a nosy neighbor with a glass pressed against the wall. Is it recording everything?
Here is the good news: For the most part, your smart speaker is napping. It has one job, and that is to listen for its specific “Wake Word”—usually “Alexa,” “Hey Google,” or “Siri.”
Think of your smart speaker like a doorman at a very exclusive club. This doorman ignores all the chatter on the street—the traffic, the birds, the people arguing about pizza toppings. He is only listening for one specific password. Until he hears that password, the door stays shut, and nothing gets recorded or sent to the “cloud.”
However, once you say the magic word, the doorman wakes up, opens the door, and starts taking notes. This is where the real science begins.
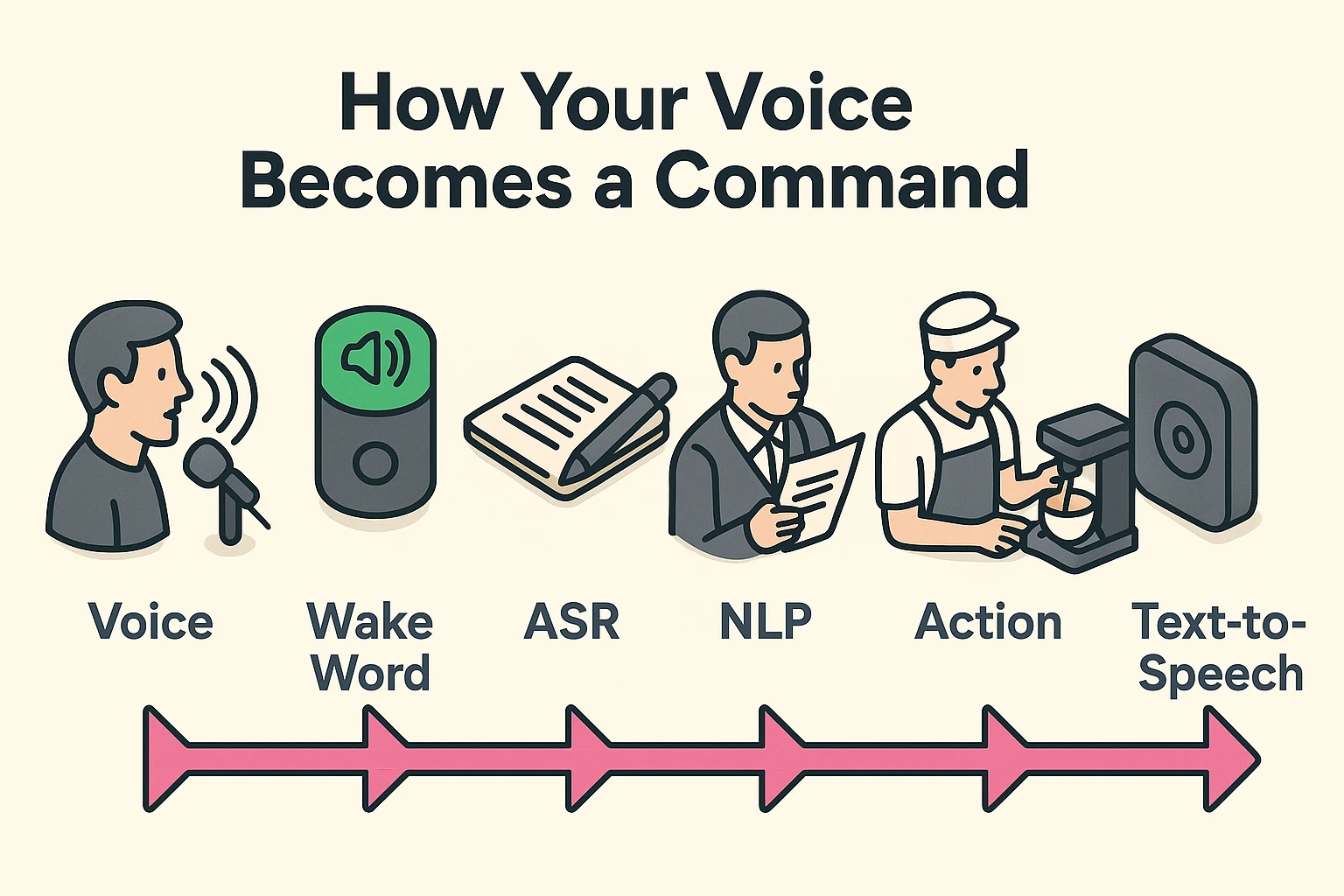
When you speak to a human, they hear your words and understand your meaning simultaneously. Computers, however, have to break this down into two very distinct steps. If they mess up step one, step two is doomed (which is why you end up listening to 1920s jazz instead of baking cookies).
The moment you speak, your device isn’t hearing words; it’s capturing sound waves. It acts like a court stenographer who types incredibly fast but has absolutely no idea what the trial is about.
This technology is called Automatic Speech Recognition (ASR). The device takes the vibrations in the air (your voice) and chops them up into tiny slivers of sound called “phonemes.” It then races through a massive dictionary to match those sounds to words.
It’s trying to figure out if you said “Ice cream” or “I scream.” To the device, these sound almost identical. It has to make a best guess based on the sounds alone. This is why background noise, like a running dishwasher or a barking dog, can cause the stenographer to make typos.
Once the “stenographer” has transcribed your sounds into text, it hands that text over to the “analyst.” This implies the brainier part of the operation, known as Natural Language Processing (NLP).
The analyst reads the text and tries to figure out your intent. If the text says “Play The Eagles,” the analyst has to decide: Does this human want to hear the 1970s rock band, or do they want to watch highlights of a Philadelphia football game?
The analyst looks for clues. If you usually listen to music at 8:00 AM, it guesses the band. If it’s Sunday afternoon, it might guess football.

If the tech talk is making your eyes glaze over, picture a busy coffee shop.
We have sent people to the moon, yet Siri still struggles to call your daughter “Karen” instead of your dentist “Sharon.” Why is this technology still so glitchy?
Usually, it comes down to ambiguity. Human language is messy. We use slang. We trail off at the end of sentences. We say things like, “Give me a ring,” which could mean “call me on the phone” or “purchase jewelry.”
When a smart speaker fails, it’s usually because we stumped the Analyst (NLP). We gave a command that was just vague enough to confuse the computer logic. For example, saying “Play something new” is a nightmare for a computer. New to you? New to the world? A new genre?
To be this smart, these devices need help. The little plastic speaker in your living room isn’t actually doing the thinking. It doesn’t have a big enough brain.
When you speak a command, that audio snippet is zipped off to the “Cloud”—which is just a fancy word for massive computers owned by Amazon, Google, or Apple. These massive computers do the heavy lifting (the ASR and NLP work) and send the answer back to your house in a split second.
This is the trade-off. To get the convenience of voice control, a tiny piece of your voice recording has to leave your house to be processed. While companies strip away your name to keep it anonymous, it’s always smart to check your privacy settings if you are uncomfortable with this.
Please don’t. Speaking slowly and loudly actually distorts your natural speech patterns, making it harder for the ASR to recognize the words. Speak naturally, perhaps just slightly clearer than you would to a friend.
This is called a “false positive.” The TV or a conversation might have produced a sound that was mathematically similar to the wake word. For example, “Alex loves…” sounds a lot like “Alexa.”
Most devices have a physical “Mute” button (usually looks like a microphone with a line through it). When this is red, the microphones are electrically disconnected. The doorman is off duty.
Now that you know how the sausage is made—or rather, how the voice command is processed—you can speak to your devices with a bit more authority. Remember, they aren’t ignoring you to be rude; they are just furiously trying to match your sound waves to a dictionary.
If you are finding yourself frustrated with technology, don’t worry. We have all been there. The key is to keep learning, stay curious, and maybe keep a manual timer handy for those cookies—just in case Alexa decides it’s jazz time again.